How We Cut Token Count by 11% and Boosted Success Rate by 3.9% Using HTML Instead of JSON in LLM Calls (Updated June 2026)


Every time Skyvern takes an action on a web page, it sends an annotated screenshot plus a structured description of every interactable element to a multimodal LLM: buttons, inputs, dropdowns, the works. That description is where a lot of tokens go. We'd been representing those elements as JSON, which is readable and explicit, but also verbose. After hearing from others in the space that HTML and markdown representations could cut token counts by 15% or more, we decided to test it ourselves. The results were better than expected on cost, and surprising in a way we hadn't planned for.
TL;DR
- Skyvern sends a textual representation of interactable page elements to an LLM alongside screenshots, and that representation was consuming a large share of our input token budget.
- HTML encodes the same element data in 20 to 27% fewer tokens than JSON, based on spot checks with the OpenAI tokenizer.
- We ran an A/B test on ~1,100 production tasks comparing JSON vs. HTML representations.
- HTML cut our median cost per task by 11.4% (from $1.22 to $1.08 on successful tasks).
- It also raised our success rate by 3.9% (from 59.9% to 63.8%).
- Our hypothesis for the success rate gain: shorter context reduces LLM hallucinations, a counterintuitive but well-supported side effect of the token cut.
What’s Skyvern?
Skyvern is an open-source AI agent that helps companies automate browser-based workflows with AI. You can use Skyvern to automate actions on any website with natural language: simple objective-based problems. Examples include going to www.geico.com and prompting it with “generate an auto insurance quote”.
What’s the problem?
Skyvern identifies and annotates elements on the screen and generates metadata about the interactable elements. It sends both an annotated screenshot + metadata about the interactable elements to a multi-modal LLM (such as GPT-4O or Claude 3.5 Sonnet) to decide what actions to take to accomplish a users' goal.
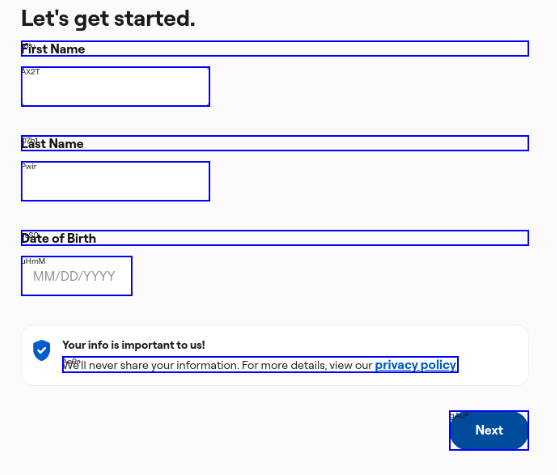
Within that operation, a substantial portion of input tokens, our biggest cost driver, is consumed by the context associated with interactable elements. Token costs compound fast: Skyvern runs actions in a loop, sending a fresh payload to the LLM on every step. A single task might require a dozen or more individual actions (clicks, form fills, waits, confirmations), and the element tree gets sent each time. At scale across thousands of daily tasks, the format of that data is not a detail. It's a budget line.
In practice, Skyvern uses the annotated screenshot plus a textual representation of the interactable elements to ground an LLM's responses and reduce hallucinations when working through random websites.
For the above screenshot, the grounded element tree includes elements that look like this:
{
"id": "Pwir",
"interactable": true,
"tagName": "input",
"attributes": {
"name": "Id_GiveLastName_21593",
"type": "text",
"maxlength": "20",
"aria-label": "Last Name"
},
"context": "Last Name"
},.
Given that token counts are highly coupled with running costs, we wanted to test alternative data representation methods.
We talked to other founders building LLM-powered automation tools, and came across community reports suggesting markdown & HTML could compress prompts by over 15% compared to JSON [1]. Markdown wouldn't be useful to us because we want to encode tag-related information (ie input) inside the information passed to the LLM.
Experimentation
Step 0: Do basic spot checks
Before digging too deep, we wanted to just do a spot check to assert that we expect data represented as HTML takes fewer tokens than JSON using the OpenAI tokenizer tool.
Sample Prompt + Element Tree (HTML):
// number of tokens: 31
<input id="Pwir" name="Id_GiveLastName_21593" type="text" maxlength="20" aria-label="Last Name">
Sample Prompt + Element Tree (JSON):
// number of tokens: 70
{
"id": "Pwir",
"interactable": true,
"tagName": "input",
"attributes": {
"name": "Id_GiveLastName_21593",
"type": "text",
"maxlength": "20",
"aria-label": "Last Name"
}
}
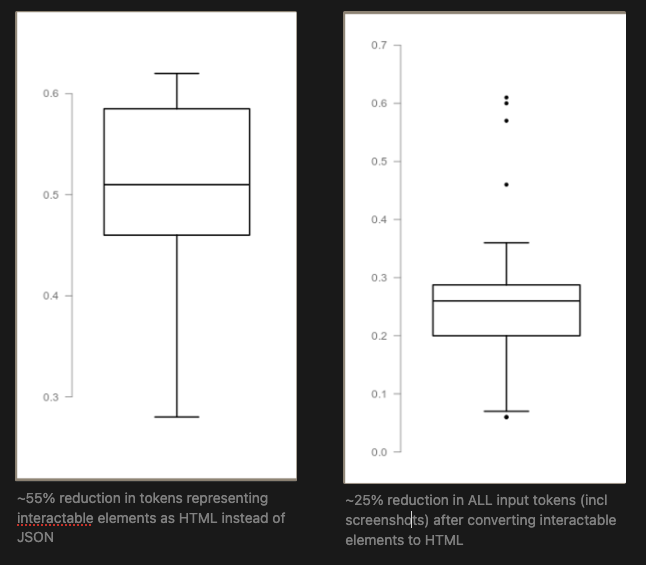
Expanding this to a set of past Skyvern tasks, we can see that representing our data as HTML will reduce our result in approximately 20-27% Savings
Step 1: Test in production
The primary goal of this experiment was to reduce running costs without compromising the performance of Skyvern. To achieve this, we conducted an A/B test in production using this new setup.
For the A/B test, we divided tasks evenly between the original JSON representation and the new HTML representation. Tasks were assigned at the start of each run, so the split was consistent across the full duration of the test. We tracked success and failure rates on real customer tasks, not synthetic benchmarks, because task completion is the direct measure of value for our users.
A task counts as a success when Skyvern completes the goal the user specified: a form gets submitted, a quote gets generated, a file gets downloaded. A failure is any run that ends before that goal is reached, whether because the agent got stuck, made a wrong action, or hit an unrecoverable page state. Cost was measured as actual LLM spend per task run, using the median (p50) to smooth out the tail of unusually complex tasks.
Step 2: Look at the test Results
We ran the test on over ~1,100 tasks within Skyvern. Here’s the final breakdown:
Experiment | Status | Number of tasks | Net cost (p50) | Success rate |
|---|---|---|---|---|
HTML | success | 332 | 1.08 | 63.8% |
failed | 188 | 2.82 | ||
JSON | success | 391 | 1.22 | 59.9% |
failed | 261 | 3.13 |
Success Rate Impact:
- Overall, a 3.9% improvement in success rate
- JSON representation: 59.9% success rate
- HTML representation: 63.8% success rate
Cost Impact:
- Overall, a 11.4% reduction in net cost
- JSON representation: 1.22 average cost per task
- HTML representation: 1.08 average cost per task
Counterintuitive learnings
We accomplished the goal we set out to do. We reduced our operating costs by 11.4%.
But something counter-intuitive also happened: we also improved our success rate. Why?
Our working hypothesis is that by cutting down the total context we're sending to an LLM, we've reduced the rate of hallucinations that long context windows can introduce. This is supported by published research on how attention degrades over long sequences. A 2024 study on LLM behavior under extended context found that models lose reliable recall of information placed in the middle of long inputs. The intuition runs counter to what you might expect: more information should mean better decisions. But LLMs don't process context the way a human skims a page. Token position matters. Redundant or verbose content early in the context can push the signal further from where the model applies attention. With JSON, every element came wrapped in structural boilerplate (brackets, quotes, key names) that carried no task-relevant information. HTML strips that down to the tag and its attributes, which is exactly what the model needs.
There's also a simpler version of the same argument: shorter prompts leave less room for the model to anchor on the wrong thing. A dense JSON block describing 40 elements gives the model 40 places to misread intent. The equivalent HTML block, carrying the same element data in fewer tokens, shrinks that surface area. The 3.9% improvement in success rate is, on this reading, a direct downstream effect of reducing noise — not an accident of the format change.
Final Thoughts
We set out to cut costs. What we got was a cost reduction and a reliability improvement from a single, low-risk representational change. No model swap, no prompt engineering overhaul, just a different way to encode the same information.
The lesson, though, is broader than token counting. If your system sends structured data to an LLM at high volume, the format of that data matters in ways that go beyond readability. HTML's concise attribute syntax packs the same semantic content into fewer tokens, and fewer tokens mean less noise for the model to work through. That appears to pay dividends in accuracy, not just cost.
For any team running LLM-heavy workloads where structured element data is passed on every call, this is a low-effort experiment worth running. Swap the representation, run an A/B test on a sample of production tasks, and measure both cost and success rate. The results may surprise you the same way they surprised us.
If you're curious how Skyvern handles browser automation at scale, or want to see how these kinds of optimizations play out in practice, book a demo and we'll walk you through it.
FAQ
Still have questions about the experiment or how this applies to your own LLM workloads? Here are the answers to what people ask most.
What is Skyvern?
Skyvern is an open-source AI agent that helps companies automate browser-based workflows with AI. You can use Skyvern to automate actions on any website using natural language. For example, going to www.geico.com and prompting it with "generate an auto insurance quote."
What problem was Skyvern trying to solve with this experiment?
Skyvern sends a textual representation of interactable page elements to an LLM on every action. That context was consuming a large share of input tokens, our biggest expense. Token counts are tightly coupled with running costs, so we wanted to test whether a different data format could bring those numbers down without hurting task performance.
What were the main results of switching from JSON to HTML representation?
HTML cut our median cost per task by 11.4% (from $1.22 to $1.08 on successful tasks) and raised our success rate by 3.9% (from 59.9% to 63.8%). Spot checks with the OpenAI tokenizer showed HTML encoding the same element data in 20–27% fewer tokens than JSON.
Why did the HTML representation improve success rates?
Our working hypothesis is that shorter context reduces LLM hallucinations. By trimming the total input, we appear to have reduced the noise the model had to work through, a counterintuitive side effect of the token cut, but one that is well-supported in the research literature.
How was the experiment conducted?
We ran an A/B test in production, dividing tasks evenly between the original JSON representation and the new HTML representation. We tracked success and failure rates on over 1,100 customer tasks, which is the direct measure of how users get value from Skyvern.