Asking AI to build scrapers should be easy right?

TL;DR - We just gave Skyvern the ability to write and maintain its own code, making it 2.7x cheaper and 2.3x faster. Give it a prompt (or a series of prompts), and the AI will generate and maintain playwright code while it runs. Try out the via Open Source or Cloud
💡 Recap: What is Skyvern? It’s an open source tool that helps companies automate things in the browser with AI. We use computer vision + LLMs to turn prompts into automations that run. We serve both technical and non-technical customers, and have helped them automate things like applying to jobs, fetching invoices or utility bills, filling out government forms, and purchase products from hundreds of different websites.
Asking AI to build scrapers should be easy right? Right??
Some of you may remember our Hackernews launch from last year. All of the discussion circled around the same idea: “Building the automation is the hard part… we just want Skyvern to write the code”.
We agreed. Keeping the agent in the loop means invoking an expensive and non-deterministic LLM call on every run. If Skyvern could compile its reasoning into code and run that instead of keeping an LLM in the loop, automations would become faster, cheaper, and more reliable.
So we tried to teach Skyvern to do exactly that… but it turns out, asking AI to write code the same way you and I would wasn’t easy. We ran into two big problems:
- Requirements for automations are ambiguous at best, and misleading at worst — even humans struggle to define them clearly
- The internet is messy: drop-downs masquerade as textboxes, checkboxes that are always checked, and search bars that are secretly buttons.
Getting an agent to navigate that chaos, understand intent, and still produce maintainable code came through one major breakthrough: reasoning models.
Reasoning models unlock two important capabilities:
- They boosted the agent accuracy enough for production use
- They let the agent leverage its trajectory to write a script resembling something an engineer would write
This is too abstract. When does this matter?
Before we dive into the solution, let’s look at a real-world example: Registering new companies for payroll with Delaware.gov
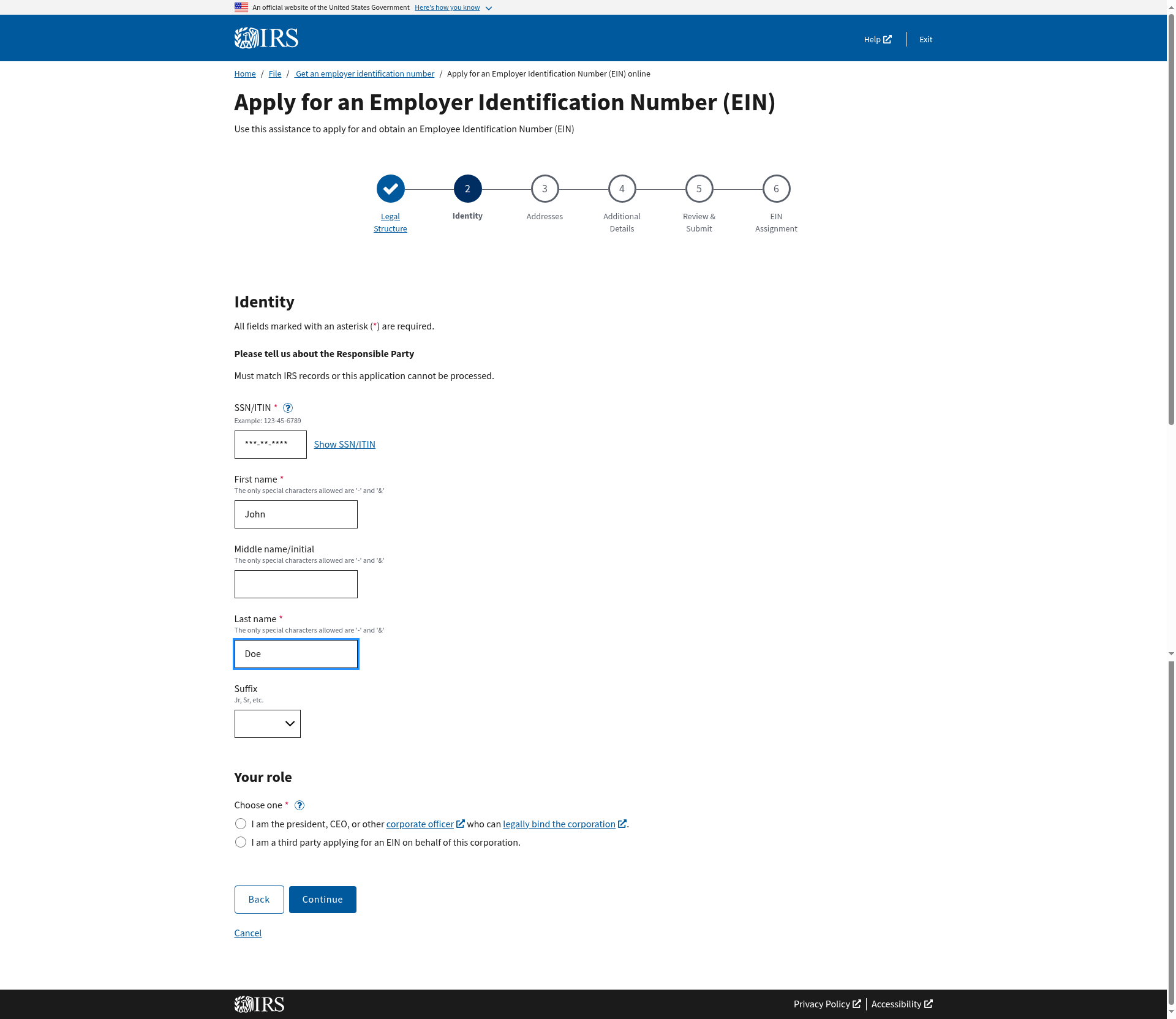
Here’s a simple prompt that reliably powers the workflow:
Your goal is to fill out the EIN registration form. Fill out the form until you're at the form confirmation page with a summary of all information. Your goal is complete once you see a summary of all of the information.
ein_info: {{ein_info}}
Writing deterministic code should be easy right?
Here’s what a naive AI Generated implementation looks like:
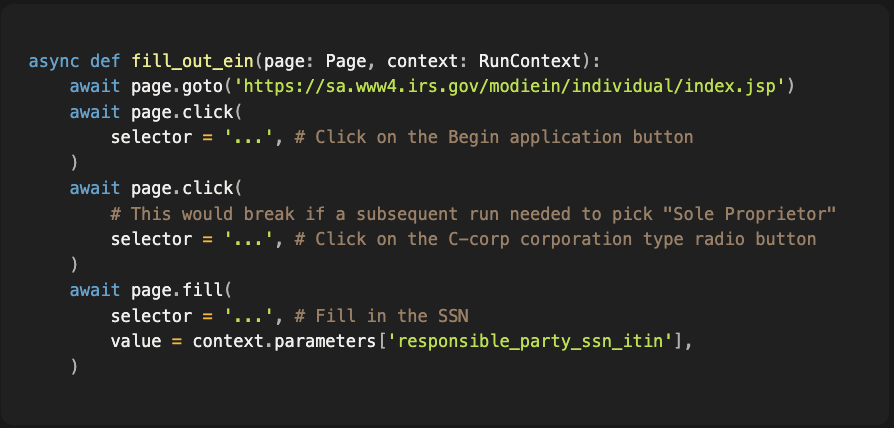
And here’s where it falls apart almost immediately.
- Coupled interactions. Choices on this form aren’t independent. Sometimes radio buttons are linked together, but aren’t represented as such in the DOM. Other times, different buttons trigger different follow-up questions, so a static script breaks as soon as you pick something unexpected.

Random failures. Government websites love to go down at night, change field layouts between sessions, or throw you a “try again later” page mid-run.

Coupled interactions
Consider the radio button example above. Any seasoned developer would know that these legal structures are linked together. You’d instinctively model them as a finite set of entity types, and create a tree-like script that branches into different paths based on the input.
But that abstraction doesn’t exist for an agent. To agents like Skyvern, this is just a list of buttons. The relationship between the users’ input and the available set of legal structures doesn’t exist ahead of time — it must be discovered at runtime.
The agent has to infer, from the DOM and the page transitions, which choices lead where.
Random non-deterministic failures
Agents shine when things don’t go as planned. We don’t want to hard code every single edge case when compiling an agent into a deterministic script.. because we’re back to writing brittle scripts. Instead, we want to leverage agents for these situations.
Take this government form: Delaware’s portal is unavailable at night or over the weekend. Or sometimes, it’ll require you to call the IRS or sending them a fax / mail to proceed with the form. You want some intelligence in the loop to handle these scenarios gracefully.
So.. how can you codify this in an agent?
After a few runs like the ones above, we realized “have the agent write code” wasn’t enough. We needed to copy how developers actually work: figure out the flow, add logic where it breaks, and bake that behavior into Skyvern.
So we split its job into two:
- Explore mode, where the agent learns how to navigate a website for a given flow, generating any metadata necessary for it to operate in subsequent runs
Replay mode, it compiles those learnings into deterministic Playwright and runs fast and cheap, only falling back to the agent when something new or weird happens
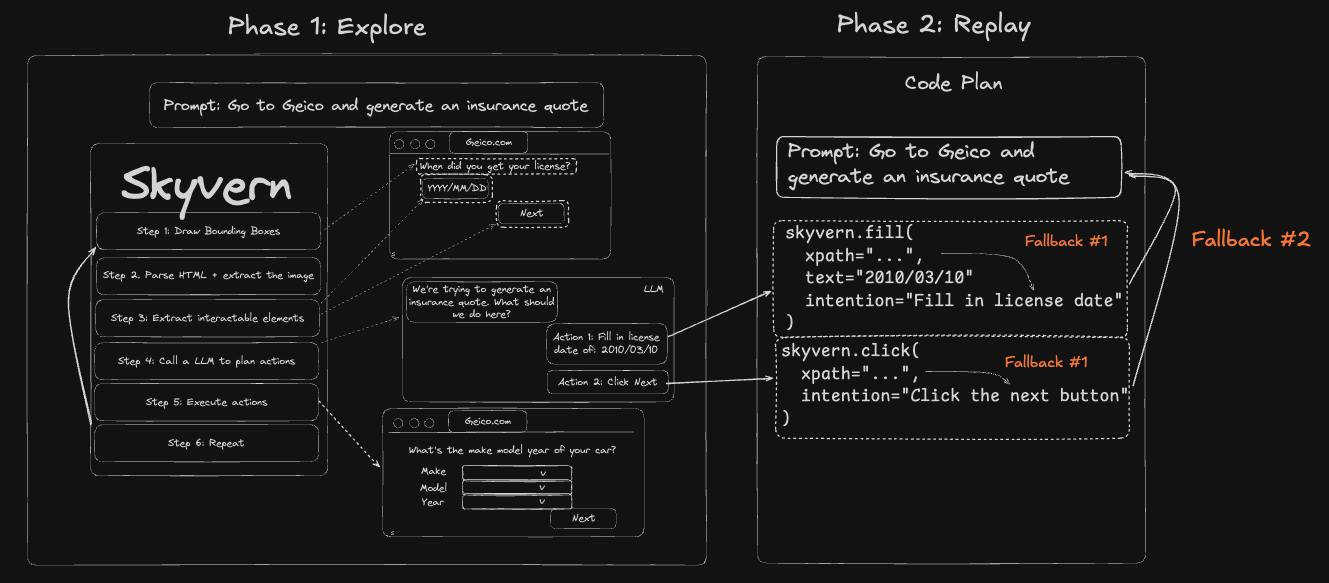
Explore once: get the agents’ trajectory
Let’s start with a plain prompt for Skyvern. The ein_info field is just a json blob with all of a company’s metadata (entity type, responsible party, etc). The goal of this explore run isn’t to finish fast, it’s to learn the flow and record a trajectory we can compile later.
Go to https://sa.www4.irs.gov/modiein/individual/index.jsp
and generate an SS4 with the following information: {{ ein_info }}
Step 1: generate a naive script
From that trajectory, the agent can spit out a basic Playwright script. It runs, but it’s brittle—no context, no fallbacks:
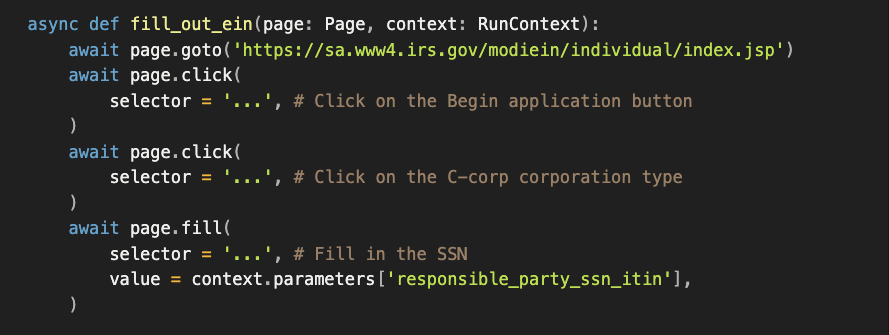
What’s missing: it doesn’t know why it’s clicking “Corporation,” what should appear next, or how to recover if the DOM shifts (or the portal is down). That’s the gap we close in the next section (intent metadata + deterministic replay with targeted fallbacks).
Step 2: Ask the agent to write down its intention so we can re-use it later
Exploration gives us a working script, but it’s brittle because it only knows what to click, not why. The fix was to capture intents to every action so the run can recover when the page shifts.

To get to this intention, we generate 2 additional parameters at runtime: user_detail_query and user_detail_answer to capture the essence of the action (beyond the interaction itself)
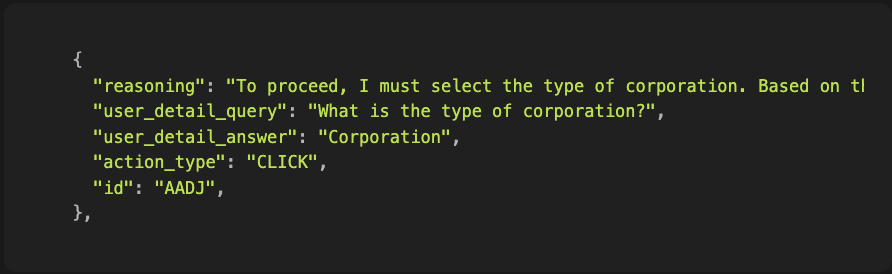
Then, we pass it through another LLM call to reverse engineer the action into the following:
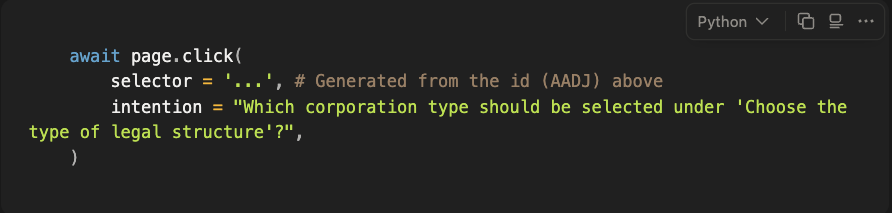
If this fails at replay time, we don’t blindly guess a new selector—we reuse the intention to recover:
- Try an alternate selector for the same intention (looser match, nearby label, aria text)
- If the flow changed, ask the model once: “How do I ‘Select legal structure: Corporation’ on this page?”
- If we hit a dead end (downtime/error), fallback to the original prompt to decide what to do next
At this point, we have generated code that looks like this:
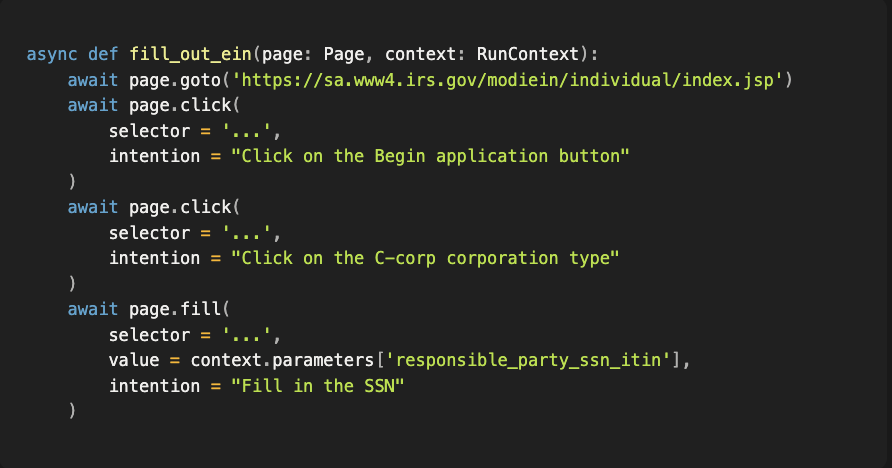
Step 3 - Run it on the cheap
Now that we have a plan and a fallback in place, subsequent runs are all using plain playwright — no LLM in the loop.
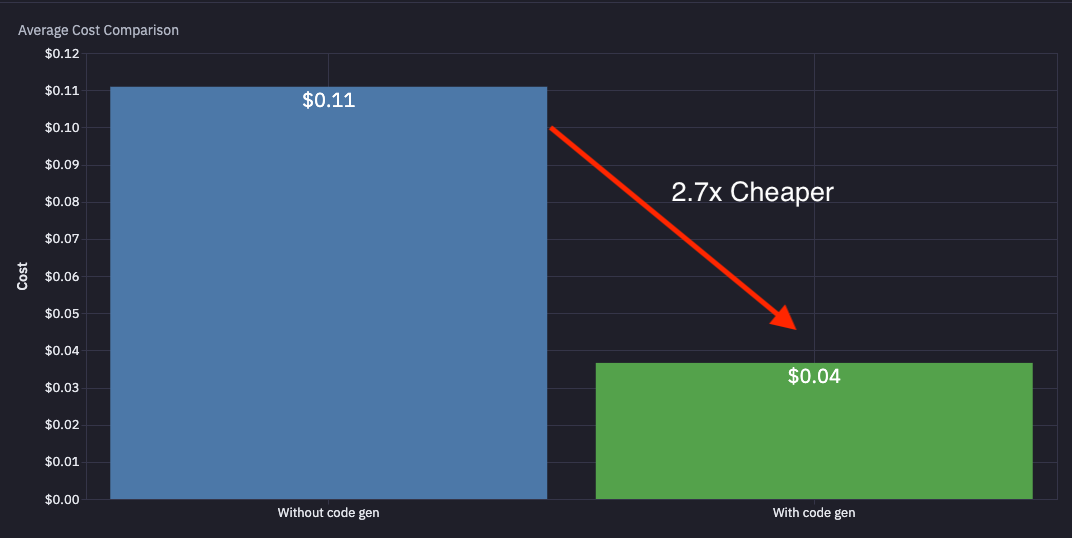
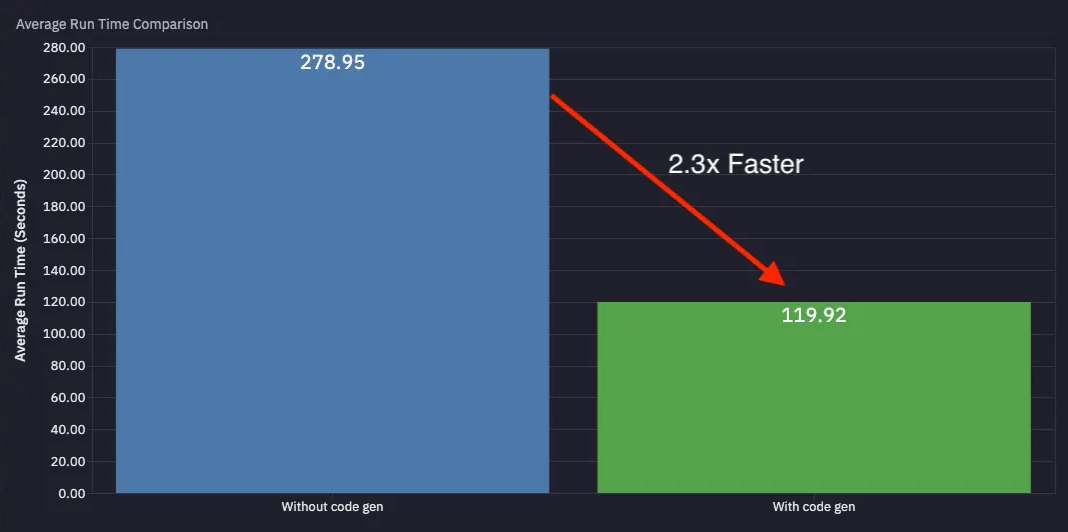
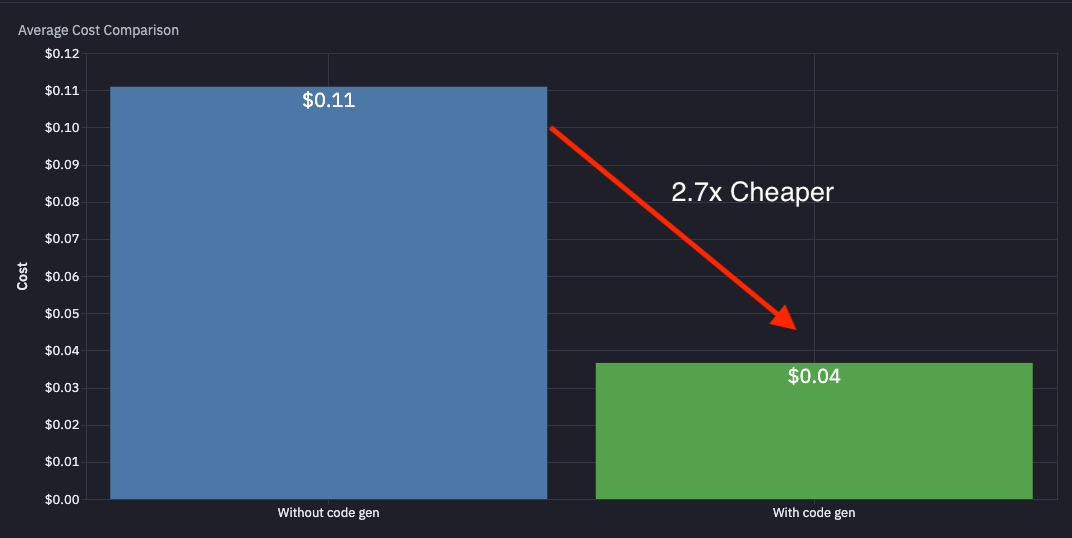
We benchmarked this across our customers and saw:
- Average automation run time goes from 278.95s → 119.92s (2.3x faster)
- Average run cost goes from $0.11 → $0.04 (2.7x cheaper)
- And maybe more important than either: runs are now deterministic.
How is this being used in the wild?
Skyvern’s “explore → replay” pattern is already running quietly inside a bunch of workflows that used to require brittle, human-maintained scripts. A few examples:
- Invoice Downloading
Agents log into vendor or utility portals with 1000s of different accounts, navigate to the right billing period, and pull invoices. When layouts or date filters change, the intent metadata lets them recover automatically instead of failing.
- Purchasing
Teams use it to automate repeat purchases — think renewing software licenses or buying supplies through the same vendor dashboard each month. The first run learns the checkout path, the fallbacks handle the variety of products, and the replays run deterministically, flagging if a price or SKU changes.
- Data Extraction from Legacy Systems
Skyvern navigates authenticated dashboards, scrapes tables or PDFs, and pushes the structured output into into a database via Webhooks. If the DOM shifts, Skyvern reuses the same intention (“extract transaction rows”) to remap selectors.
- Government Form Filling
From payroll registration to business license renewals, Skyvern handles long, multi-step government forms that occasionally break static scripts. Explore mode figures out the flow once replay mode repeats it safely.
What’s next? Is it perfect today?
Not quite. The architecture works well, but there are still a few places where we can make it smarter and cheaper:
- Analyze groups of runs when generating code.
Right now, we don’t aggregate insights across failures. Each replay fixes itself in isolation. If we could analyze many runs together, spotting which selectors break, which flows diverge, we could automatically generalize better code and reduce the need for fallbacks. That’s especially useful for workflows that branch like trees (different inputs → different paths).
- Cache data extractions.
During data extraction, we still rely on the LLM to “read” the page each time because many of our users want to both extract and summarize information at the same time. For example, if you ask Skyvern to pull the summaries of the top five posts on Hacker News, it currently parses the DOM from scratch. We’d like to trace how the model found those elements (which selectors, which substrings) and reuse that mapping. That alone could make scraping and data-harvesting flows an order of magnitude cheaper.
- Expose everything through the SDK.
We think it will be valuable for developers using the Skyvern SDK to auto-generate these scripts for any ai actions / workflows they run, and use them automatically for subsequent runs. It currently requires a Skyvern server running, but soon it will be the default behaviour.
Give it a try!
Run it via our Skyvern Open Source or Skyvern Cloud versions and let us know what you think!